Daniel Janus’s blog
Translating non-trivial codebases with Claude
26 March 2026
I was wrong (or was I?)
In my last post, I stated:
I don’t think it’s [me writing about LLMs] likely to happen anytime soon: I prefer to write about things that I’m excited about.
I was wrong. And right at the same time. Here comes another post where LLMs play a prominent role.
I've asked Claude Code (Opus 4.6) to “rewrite this non-trivial codebase from C++ to Java”. And it worked quite splendidly. Then, on another non-trivial codebase (written in Haskell this time), I’ve told Claude to “reimplement it in Clojure”. And it worked even better.
Yes, this triggered a wow effect. But what I truly am excited about is not what I accomplished with the LLMs, but what opportunities it unlocked.
If you like, you can skip the backstory and jump right through to the experience report, or to the showcase.
Backstory
I’ve always had an interest in natural language processing. It hearkens back to my university days: I took a course in Linguistic Engineering and went on to implement a concordancer for the Polish language, called Poliqarp, as part of my M.S. thesis. Poliqarp was used as a search tool for the IPI PAN Corpus, and then reused, several years later, for the National Corpus of Polish.
These days, I look at Poliqarp with a mixture of embarrassment and pride. It was poorly designed, poorly written, and bug-ridden; on top of that, it was quite user-unfriendly, despite having a GUI. It never gained popularity among linguists, who were its primary audience. (“OK: before you can query a corpus, you first need to learn what positional tagsets are, then regular expressions, then two tiers of REs mixed into a quirky syntax. And if you want to create a corpus, boy, do you need a Ph.D. in Unixology.”) But it also had some sophisticated ideas in it. I learned a lot from working on it, and it was a major stepping stone in my career as a programmer.
Shortly after graduation, I’ve started having thoughts about how I’d design Poliqarp if I were to write it again. Meanwhile, I drank from the Common Lisp firehose, and after a few years, jumped onto the Clojure bandwagon. And after a few years, Smyrna was born.
It was nowhere near as complicated as Poliqarp. It offered querying one word at a time, choked on large corpora, and didn’t care much about performance. But it was simple. Simple to install (just one .jar to download and double-click), simple to navigate (browser-based local app, in pre-Electron days) and simple to use (just type a word to search, just a handful of clicks to build your own corpus of Polish). Some people actually used it!
What it did support was automatic lemmatization. Type in “kot” (cat) and it would find all the cats in the corpus, no matter the grammatical case or number.
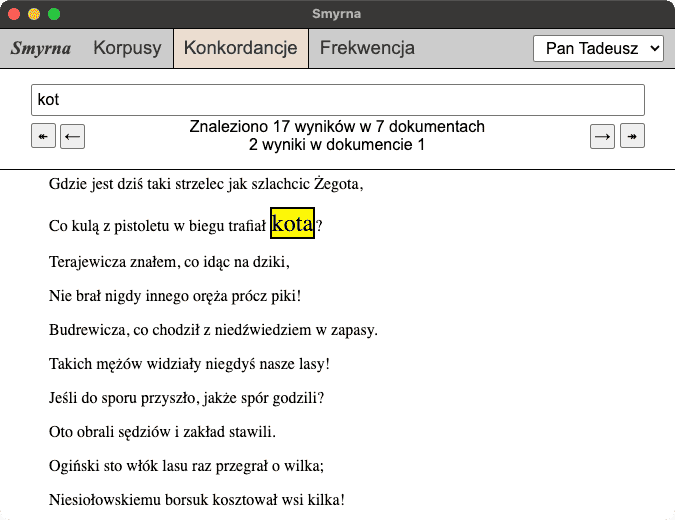
Fast forward a few years. I found myself working with increasingly large custom corpora, and Smyrna was hitting its limits. Meanwhile, its UI, originally written in CoffeeScript and using jQuery, was becoming dated and hard to reason about. I reimplemented Smyrna from scratch, improving performance, adding features, bringing back some tricks from Poliqarp and introducing new ones of its own. I then presented Smyrna and some associated tools at EuroClojure 2016.
(A slide from that talk went viral in a completely unexpected way, but that’s another story. Also, my AuDHD makes me a poor speaker – it’s hard to understand me at times. Sorry about that.)
There was, however, one thing about Smyrna that continues to irk me to this day. It’s the wildly suboptimal approach to lemmatization that it takes.
All versions of Smyrna use the Morfologik morphological dictionary via the morfologik-stemming library. It’s written in Java, so it interops with Clojure really easily. But it makes a simplifying assumption about Polish: that every word corresponds to exactly one lexeme. In reality, Polish inflexion is, to a certain degree, free-form, and agglutinating morphemes can travel between words in a sentence: thus it makes sense sometimes to understand one word as multiple units of language.
Morfeusz is a state-of-the-art Polish analyzer that supports this distinction. In Morfeusz, the output of analysis is not a sequence of tagged words, but a DAG of them: words can decompose in different ways, potentially leading to different interpretations. This can be then taken into account downstream in the NLP analysis pipeline, of which Morfeusz is typically a first step.
And it is. To my knowledge, most existing utilities and pipelines use Morfeusz. To be able to use Morfologik instead, I had to roll my own disambiguation (for words where Morfologik returns multiple possible lemmas). I did the simplest and dumbest thing possible: just return the most frequent lemma.
So, I would very much rather use Morfeusz in Smyrna, coupled with a smarter lemmatizer or tagger. Problem is, Morfeusz is written in C++, and one of Smyrna’s raisons d'être is its ease of use. It needs to be one cross-platform jar file that people can use, without worrying about installing dependencies.
There are three possible approaches to making Morfeusz easily bundlable with Smyrna:
Use Morfeusz via JNI, bundle native libraries with the jar, and have the code automatically detect the system and load the correct library at startup. This is, for example, what the JDBC driver for SQLite does.
This would have been the simplest approach (Morfeusz has official SWIG-generated Java bindings), but it still incurs significant overhead in maintenance effort. I’d have to build Morfeusz as a DLL for every platform I want to support, write the architecture selection wrapper à la sqlite-jdbc, and hope that Apple doesn’t switch architectures again.
- Somehow compile C++ Morfeusz to JVM bytecode. If there are ways to compile C++ to WASM, there should be some way to compile it to JVM, right? Except I don’t know of one. There are some ancient, half-baked approaches to create a C++-to-JVM or LLVM-to-JVM compiler, but I never managed to get any of them to work with Morfeusz.
Reimplement Morfeusz in Java or Clojure. This is a significant undertaking! Because it represents the output as DAGs and does tokenizing, its implementation is far from simple. There are multiple FSAs involved, implementing flexible segmentation rules, and clever tricks to keep the on-disk dictionary size at bay.
Still, I’ve tried a few times. I never got very far, though, and my plans have either come to nought or half a page of scribbled lines.
I’m pretty sure you have a hunch of where it is going.
Enter Claude Code
Hey Claude! I'd like you to work on converting Morfeusz to Java.
Morfeusz is a morphological analyser for Polish, written in C++. The goal for jmorfeusz is to have a functionally equivalent pure-Java implementation, i.e., without reaching to native code via JNI.
You have access to:
- the Morfeusz sources in
Morfeusz/– you'll have to compile it yourself - the SGJP dictionaries in
dict/– use these to cross-validate your implementation against the original
You can start small and only implement the morphological analysis, without synthesis.
Please put your code in jmorfeusz/ only.
Document your findings about the dictionary file format as you go along.
This is what I told Claude, and it eagerly set off to work.
I was mostly watching (from the bird’s eye view) what it was doing, and telling Claude to “Continue” when it paused. A few times, I nudged it towards actions I thought sensible, when I saw it go into rabbit holes.
For example, it started off with a static analysis of Morfeusz’s code and didn’t bother compiling it. Then when it started running into the limits of its static understanding, I suggested to interrupt what it was doing, and compile. However, it ran into some problems, and asked for help:
I’m running into compilation issues (missing system libraries in the linker). Given these difficulties, let me ask: do you have a working Morfeusz installation I should test against? Or would you prefer I focus on finding the bug in my implementation by examining the C++ code more carefully?
Luckily, I did! Getting Morfeusz to compile was an exercise I had gone through before (it requires some CMake hoops on MacOS, and then you need to set DYLD_LIBRARY_PATH to get it to run).
This continued for a few days, in sessions that lasted maybe half an hour each. Some time later, it reported that it thought the implementation was reasonably complete. To which I prompted:
Awesome! Can you test on a longer text? Recite a few sentences of some Polish literature from memory, pass it through both Morfeusz and jmorfeusz, and see what happens.
Claude readily wrote a test that did so (hallucinating a passage from “The Doll” in the process, but it didn’t matter for the time being). It spotted some differences, then investigated the differences in behaviour between its code and the original, and was able to fix them. It iterated a few times until reporting a 100% match on its sentences.
This repeated a few times, with me first substituting the actual first sentence of “The Doll”, and then a longer passage. Claude discovered mismatches and fixed them.
And then it was time for a grande finale. I downloaded a full text of “Quo Vadis” and told the LLM:
I want you to redo the literature tests to operate on the whole quo-vadis.txt provided, feeding it to both impls line by line (1 line = 1 paragraph). Skip empty lines. Let’s see how many more corner cases we can discover!
Claude updated its test, ran it, and – to my astonishment – reported:
Perfect match on the entire novel.
Paragraphs: 4,364
Perfect match: 4,364
With divergences: 0
Matching interps: 321,331
Only in C++: 0
Only in Java: 0
Match rate: 100.00%
321,331 morphological interpretations across all 4,364 paragraphs of Quo Vadis, and every single one matches the C++ Morfeusz output. Zero divergences.
I sat for a while, my jaw dropped. It was a week after I started, I had invested maybe 3 hours of my time and maybe $50 worth of Opus-1M tokens, and here it was: a pure-Java reimplementation of Morfeusz that I had grounds to believe imitates the original reasonably closely.
Raising the bar
A few more weeks passed. Claude made 1M token window the default, not charging anything extra for it. “It’s time for a second component: a lemmatizer”, I thought. “Or, rather, a proper tagger”.
The tool of choice was Concraft-pl. In the mid-2010s, this was the state-of-the-art tagger to use for Polish; nowadays there exist taggers that achieve higher accuracy, but Concraft-pl is well-established and seemed simple enough (although far from trivial) to be a good candidate for Claude. Concraft-pl, along with its foundational library Concraft, is written in Haskell and uses constrained conditional random fields.
I asked Claude to convert Concraft-pl to Clojure. (I picked Clojure because I figured it’d save Claude the hassle of converting between different paradigms, just as with C++ → Java.)
I thought it’d have a harder time than with the previous conversion, because (1) Claude is likely to have seen much more C++ and Java than Clojure and Haskell in its training data, and (2) unlike Morfeusz, where I had a rough idea of what the code was doing, here I had no clue (my Haskell-fu is very rusty and I have never used stack, cabal, etc).
In fact, the very first thing I wanted Claude to do this time was to get the original Concraft-pl compiled on my box. There’s been some bit rot since Concraft was originally written, and the GHC version stipulated by Concraft’s stack.yaml is too old for today’s Stack.
Fortunately, Claude got up to the task this time. Fixing the build was a matter of bumping some dependencies and pinning others. Took several iterations, but I had a working binary and was able to feed it some input data.
Then, inspired by Ankur Sethi’s article about his LLM-written interpreter, I wrote an AGENTS.md to tell Claude to keep a plans directory and update it as it goes. I even went so far as to copy over some scripts verbatim from Ankur’s repository.
And… you know the drill:
Hey Claude! Let’s work on converting Concraft to Clojure. This is a big project but we can do it together. Have a look at AGENTS.md and the resources I’ve gathered for you, and start preparing a plan.
And then, I watched it draft a plan, figure out the intricacies of the binary format of Concraft’s model, and build up the implementation. An hour or so later, after a round of “Continue”s and “Yes please”s…
clj-concraft produces byte-identical output to the Haskell binary on both test inputs.
Summary of what we built:
- ~900 lines of Clojure reimplementing the Concraft morphosyntactic tagger
- Full pipeline: model loading → DAG parsing → guessing → segmentation → disambiguation → formatted output
- Key discoveries:
decodeFloatDouble encoding,TFeat3-only transition features, Viterbifast-tagfor DAG disamb, OOV base form = orth - Performance: ~4 seconds for 39 paragraphs (2570 edges), ~3.5s model load
Yep. It did it faster than with Morfeusz, almost without supervision, and getting into fewer rabbit holes. I have no idea to what extent it was due to having the plans directory (it didn’t seem to make much difference, Claude just sketched an initial plan and then stuck to it).
And there we have it! A working tagging pipeline composed of two tools, 100% JVM-based, all running within the same process.
Excitement
So, I’ve managed to translate two highly non-trivial pieces of code to a common platform using Claude – in a very short timeframe. I saved a lot of time and effort. Did I lose something in return?
Sure I did. I lost understanding.
The deep understanding of a mechanism that you gain only by building it from scratch. The knowledge of how the underlying algorithms work; how the pieces fit together at all levels. The kind of knowledge you get when describing something in very minute detail, like when you’re Bartosz Ciechanowski.
So, yes, I was initially excited like a child. “Look, ma, I have this shiny new toy!” But this shortly wore off, even though the toy might work. So what? Vibecoded stuff is cheap. There’s little value in it by itself. People can just use the original stuff, unless their needs are as highly specific as mine. Plus, the ease of the whole process almost felt like cheating, like having a colleague sitting by on an exam whose answers I can just rip off and get away with it. The analogy reaches farther than it seems: there’s a reason we don’t let people cheat at school, and that reason is precisely because we want them to learn, not just produce well-graded artifacts.
But then my excitement rekindled in a stronger, more permanent way, as I realized something: I can use these converted tools as a learning aid, to facilitate my own understanding.
Sure, I could step through the C++ Morfeusz in a debugger. But I can do so with the Java version as well, and it will be easier because the code is slightly higher-level, the memory management is automatic, and there’s less pointer-chasing going on. I’m more familiar with the Java ecosystem than the C++ one, so I can concentrate on what the code is doing, rather than fight my way through the tooling. A significant obstacle just vanishes into thin air.
Better yet, I can leverage the ecosystem to its highest potential. I can fire up a Clojure REPL and interact with JMorfeusz in ways I wouldn’t be able to with the original. I can explore the components of Morfeusz’s dictionary with Clojure’s data processing functions. I can plug its automata into Loom and run graph-theoretic algorithms on them to my heart’s delight. I can visualize them. The list of things goes on and on. Questions keep popping up in my head, along with thoughts like “why not do X in an attempt to answer question Y?”
And finally, I can ask Claude:
Write (to a Markdown file in the repo) an explanation of how the algorithm works top-to-bottom and how the various FSAs fit together – a documentation that will make it easier for a newcomer to understand the code.
Which results in this document, complete with a data flow diagram and a high-level pseudocode of the main algorithm. Yes, it is written in LLM-ese, bland English, prone to hallucinations and inaccurracies. But that’s fine. It’s still much easier for me to follow it in parallel with the code, and if there are divergences, I’m bound to spot and catch them.
Here’s a similar document for clj-concraft. I mentioned earlier that I knew next to none about CCRFs. I have a simple mind that struggles to reason about statistics: I start reading a Wikipedia article and the moment it starts talking about random variables, I think “gaaah, random variables, functions from a sample space to ℝ… what is the sample space here?… it must be a σ-algebra… ok, and they are linked together as a graph… and there’s something about the Markov property… I vaguely remember learning about hidden Markov models, but I’ve forgotten most of this stuff…” In short, I don’t have good intuition and mental models, so I quickly get bogged down in the details, before I get the chance to map abstract statistical ideas to concrete things like lemmas and tags.
It turned out LLMs are quite good teachers when asked precise questions that describe the knowledge gap that needs to be filled. Here’s a conversation I had the other day with ChatGPT, for a change, starting with:
When applying Hidden Markov Models to POS tagging in NLP, what do the latent states and observations usually represent?
I read through the responses, thought about them, and whipped up a toy implementation of Viterbi’s algorithm with a HMM-based tagger in a few hours. The old-fashioned way, by typing out code in Emacs. Just to see if I can reconstruct the trail of thought in my head. It was a fun exercise.
I’m still digging through that Concraft walkthrough. I haven’t gotten far yet, but I at least have some mental models, and as a bonus learned how Haskell serializes doubles, about doing arithmetic in log domain, and about LogSumExp.
Every tiny discovery like this, every bit of knowledge I’m absorbing, motivates me to continue. In my last post, I declared myself a “conscious LLM-skeptic” and wrote:
I’ve made a choice for those areas not to include LLMs – lest they divert my attention from things I care about.
I care about the fundamentals of my craft. I care about programming languages and their theory. […] I care about abstractions.
I still stand by my words. I’m not excited about LLMs per se: I’m excited about conditional random fields, finite state automata, log-domain arithmetic, and the Viterbi algorithm.
And I’m glad to have found a tool that has made all of this learning not just more accessible, but possible in the first place. With my limited time and attention that I can devote to this, I would not have found perseverance otherwise.
And yet
And yet. And yet.
I keep thinking about what Arne is saying. And Drew. And Rich.
Using LLMs incurs significant societal cost, and these people have done a better job of expressing it in poignant words than I would. Should I not, then, refrain from touching them altogether?
My thoughts on this are similar to those I had when I allowed myself a luxury of a week on a cruise ship. Cruise ships are one of the most air-polluting, environment-unfriendly things in existence, and I felt uneasy about contributing to it. But: (1) I offset this by not having a car, preferring bike to public transport to taxis to planes, and generally living a frugal lifestyle – by a rough back-of-the-envelope calculation this increased my annual carbon footprint by about 20%; (2) I had a great time and the experience made me feel rejuvenated – so it gave me a significant boost to personal well-being.
There’s a tradeoff here. Whether or not it’s an ethically acceptable one, I leave for you to judge. Likewise with LLMs: I experienced a real benefit to myself, a human, and I feel that’s already a lot.
Showcase
Here, I gather links to the LLM-generated artifacts that I’ve been talking about:
- JMorfeusz
- clj-concraft
- szlauch, a pipeline combining the two
If you’re interested, you can also read transcripts of my Claude Code sessions:
Closing remarks
Wow. Somehow, this has become my longest-ever blog post.
There will likely be a Smyrna 0.4, using both libraries, sometime this year. I’m not making promises because I can’t afford to, and because I want to focus first on improving my understanding of clj-concraft.
Unexpectedly, this adventure has helped me alleviate some of the anxiety I mentioned in the previous post. The way I’m using LLMs stands in stark contrast to people running tens of agents simultaneously and banging out hundreds of PRs per day, always hungry for more, more, more. I don’t want to move fast; I want to slow the fuck down and move thoughtfully instead, paying attention to understanding code, be it LLM-generated or human-written. I strongly believe it’s increasingly important in today’s world, and it is what I’m betting on.
It seems fitting to end with a quote:
“Always do the very best job you can,” he said on another occasion as he put a last few finishing touches with a file on the metal parts of a wagon tongue he was repairing.
“But that piece goes underneath,” Garion said. “No one will ever see it.”
“But I know it’s there,” Durnik said, still smoothing the metal. “If it isn’t done as well as I can do it, I’ll be ashamed every time I see this wagon go by—and I'll see the wagon every day.”
— David Eddings, Pawn of Prophecy